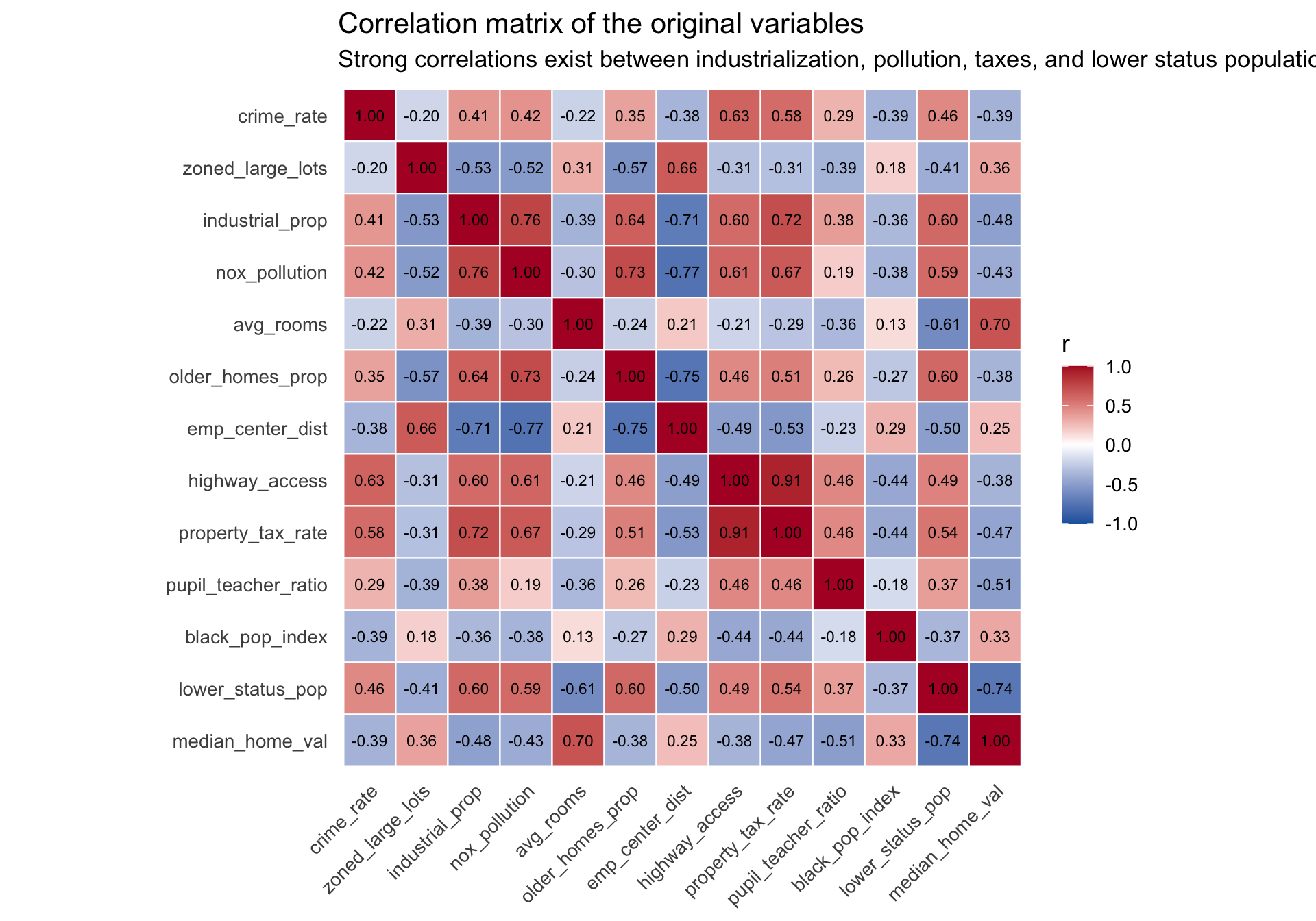
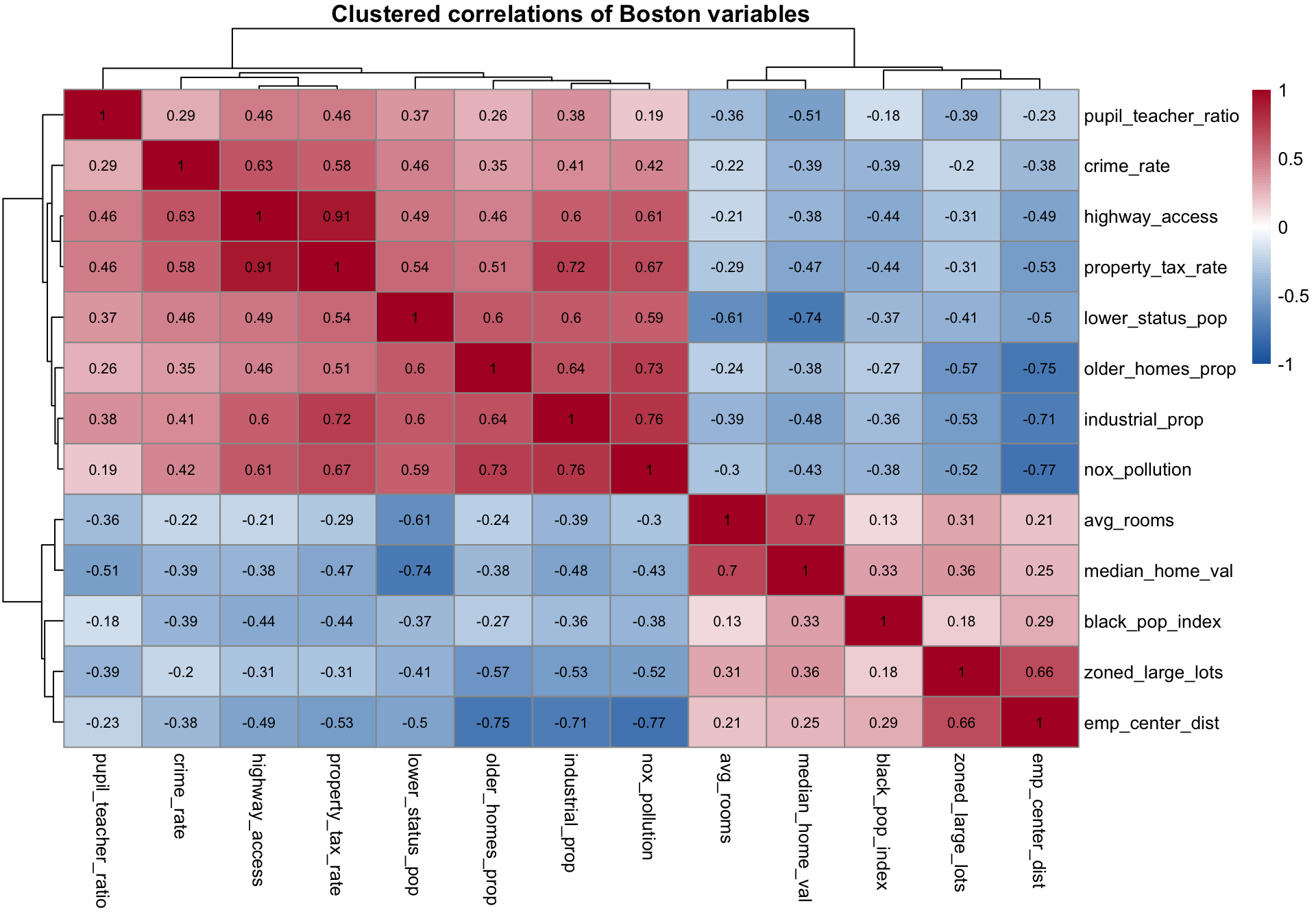
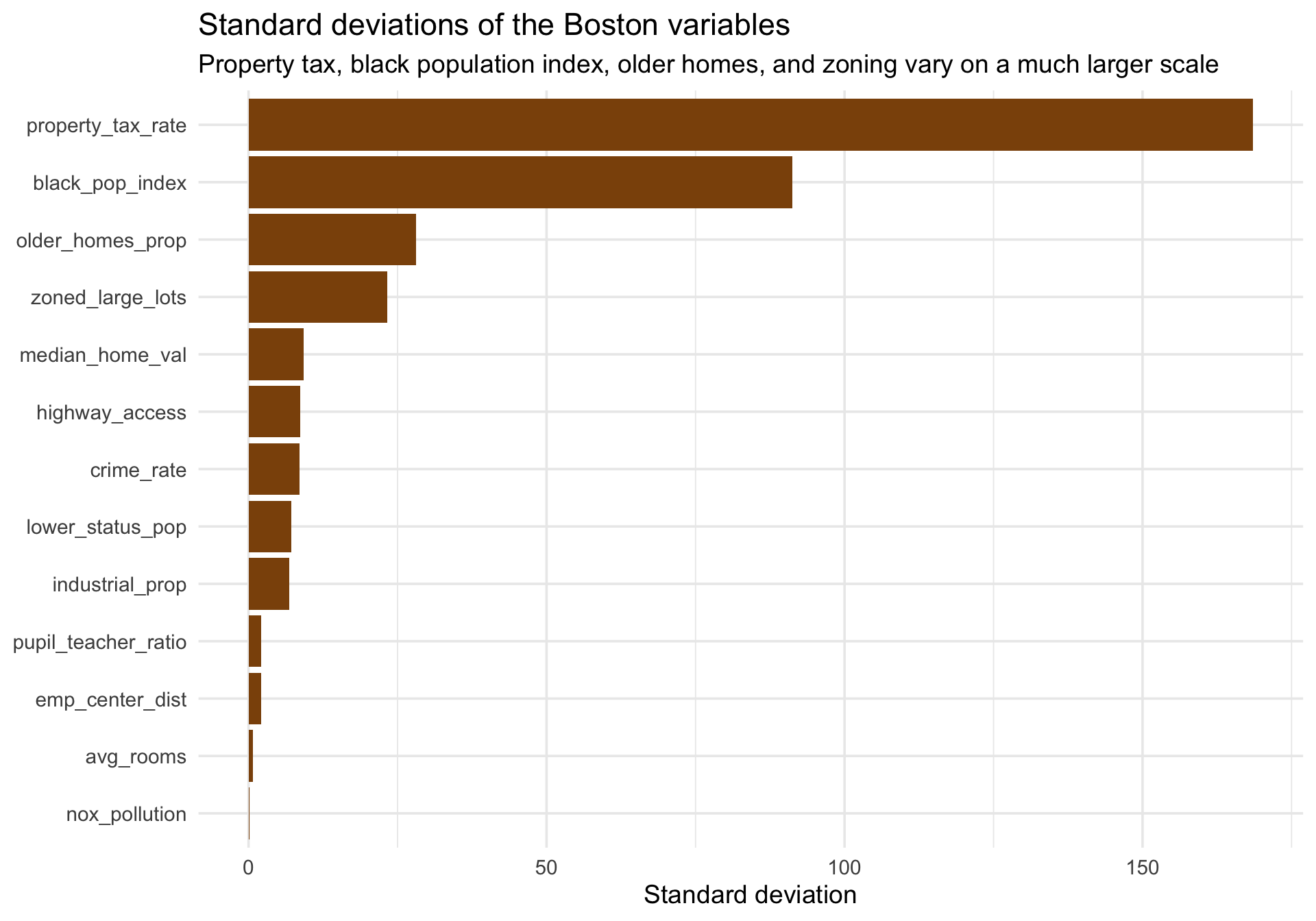
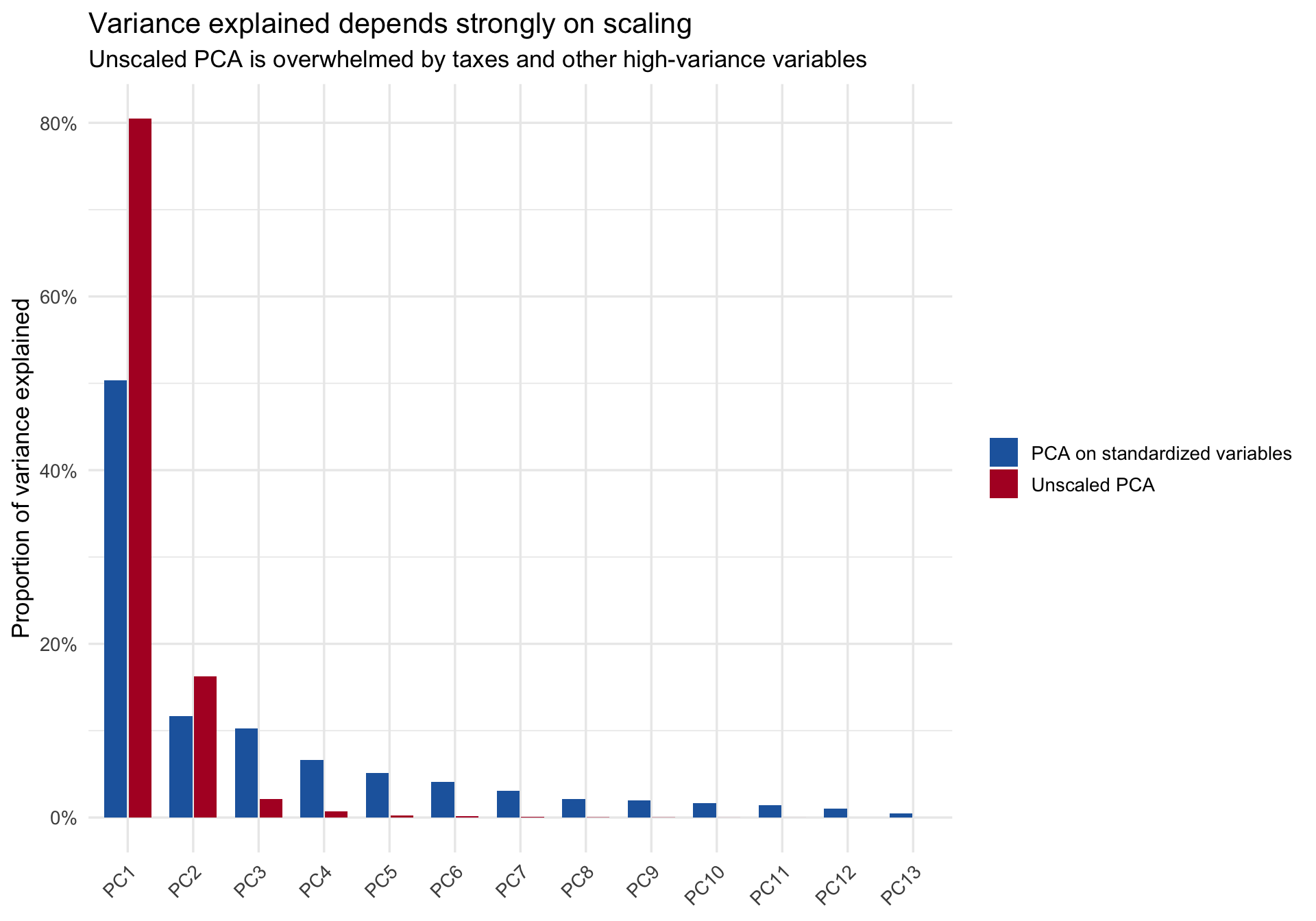
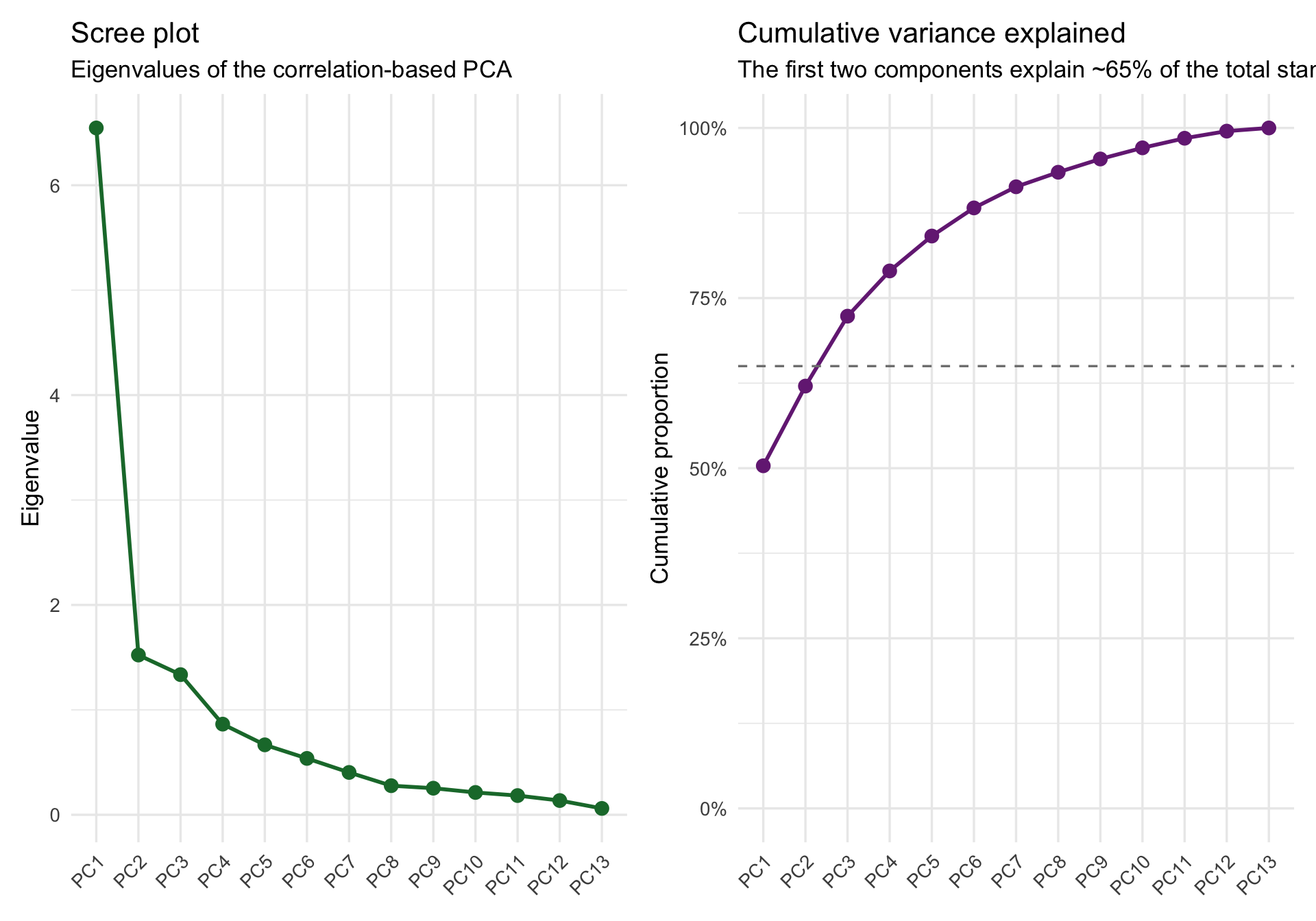
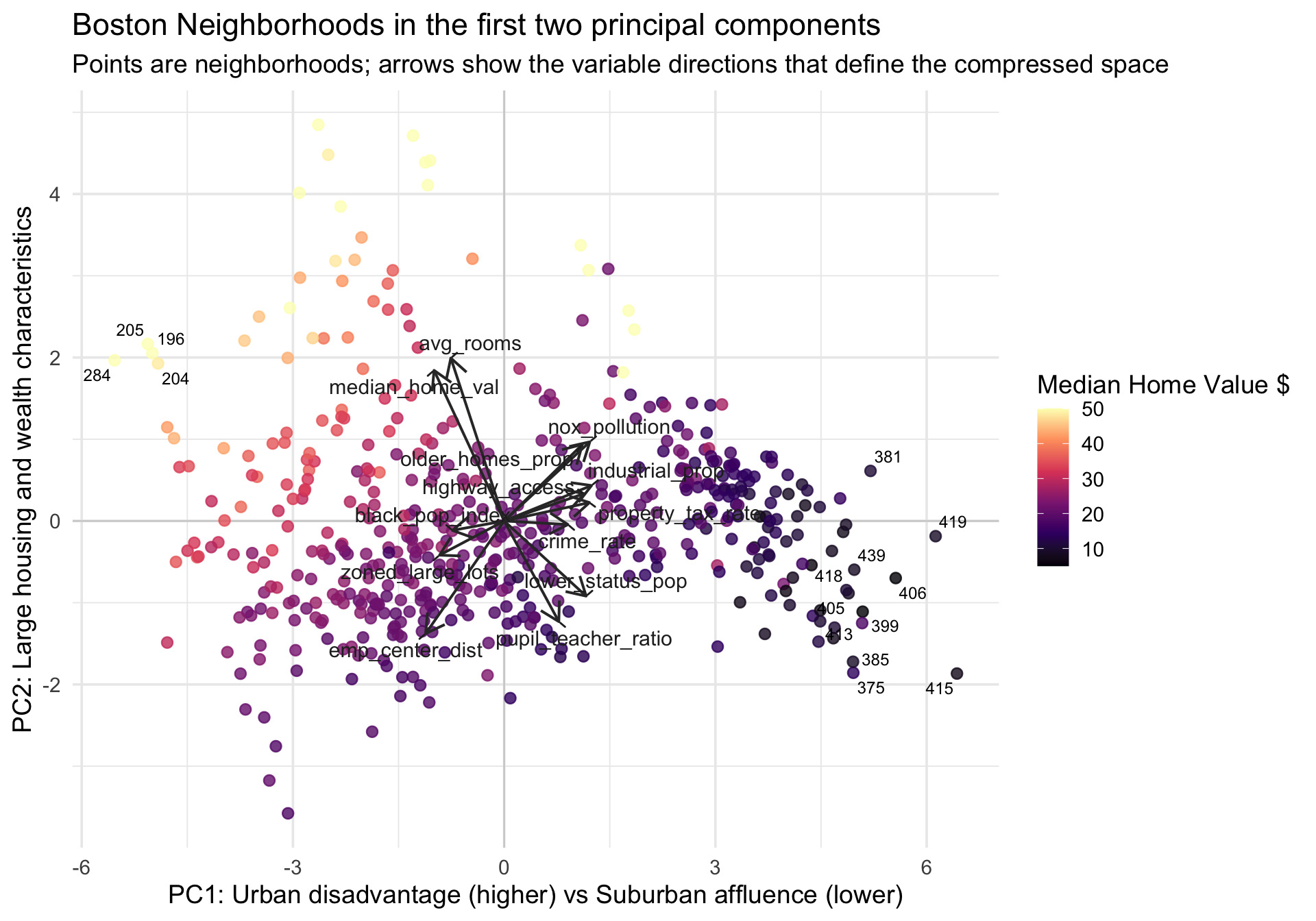
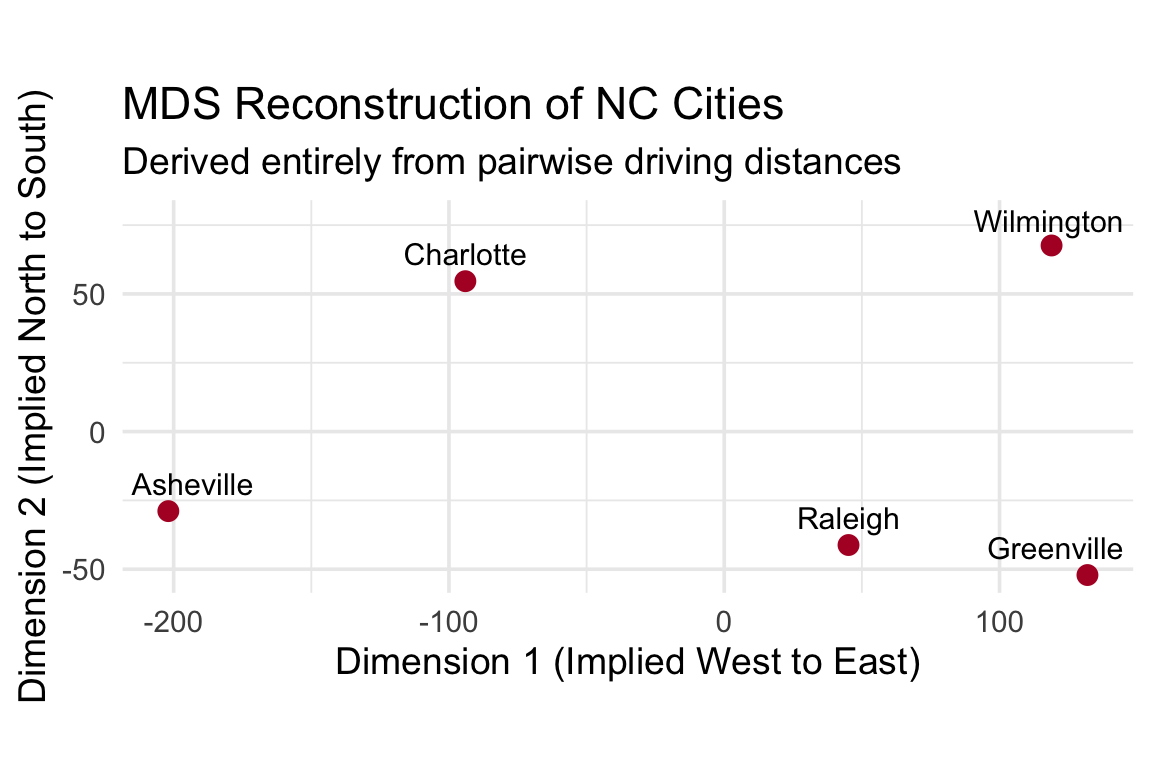
Rows: 506
Columns: 14
$ neighborhood_id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,…
$ crime_rate <dbl> 0.00632, 0.02731, 0.02729, 0.03237, 0.06905, 0.029…
$ zoned_large_lots <dbl> 18.0, 0.0, 0.0, 0.0, 0.0, 0.0, 12.5, 12.5, 12.5, 1…
$ industrial_prop <dbl> 2.31, 7.07, 7.07, 2.18, 2.18, 2.18, 7.87, 7.87, 7.…
$ nox_pollution <dbl> 0.538, 0.469, 0.469, 0.458, 0.458, 0.458, 0.524, 0…
$ avg_rooms <dbl> 6.575, 6.421, 7.185, 6.998, 7.147, 6.430, 6.012, 6…
$ older_homes_prop <dbl> 65.2, 78.9, 61.1, 45.8, 54.2, 58.7, 66.6, 96.1, 10…
$ emp_center_dist <dbl> 4.0900, 4.9671, 4.9671, 6.0622, 6.0622, 6.0622, 5.…
$ highway_access <int> 1, 2, 2, 3, 3, 3, 5, 5, 5, 5, 5, 5, 5, 4, 4, 4, 4,…
$ property_tax_rate <dbl> 296, 242, 242, 222, 222, 222, 311, 311, 311, 311, …
$ pupil_teacher_ratio <dbl> 15.3, 17.8, 17.8, 18.7, 18.7, 18.7, 15.2, 15.2, 15…
$ black_pop_index <dbl> 396.90, 396.90, 392.83, 394.63, 396.90, 394.12, 39…
$ lower_status_pop <dbl> 4.98, 9.14, 4.03, 2.94, 5.33, 5.21, 12.43, 19.15, …
$ median_home_val <dbl> 24.0, 21.6, 34.7, 33.4, 36.2, 28.7, 22.9, 27.1, 16…